")
")
| Issue |
Med Sci (Paris)
Volume 25, Number 4, Avril 2009
|
|
|---|---|---|
| Page(s) | 423 - 430 | |
| Section | Recherche et partenariat | |
| DOI | https://doi.org/10.1051/medsci/2009254423 | |
| Published online | 15 avril 2009 | |
Les biomarqueurs : « Found in translation »
Biomarkers: «Found in translation»
1
Directeur de Division, Pharmacologie et Physiopathologie Moléculaires, Institut de Recherches Servier, 125, Chemin de Ronde 78290 Croissy-sur-Seine, France
2
Directeur du Centre de Pharmacocinétique, Technologie Servier, 25-27, rue Eugène Vignat, BP 11749, 45007 Orléans Cedex 01, France
*
Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser.
*
Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser.
Résumé
L’industrie pharmaceutique a pour ambition de contribuer au progrès thérapeutique. Elle doit faire face au défi constamment renouvelé de découvrir de nouveaux médicaments efficaces et mieux tolérés pour répondre aux multiples besoins médicaux insatisfaits. Malgré les progrès thérapeutiques déjà accomplis, de nouveaux besoins sont apparus. En effet, en raison de l’évolution démographique et des modes de vie de la population mondiale, on constate une augmentation de l’incidence de certaines maladies comme la maladie d’Alzheimer, l’obésité et le diabète de type 2 et de multiples besoins médicaux non couverts émergent, en particulier dans le domaine du cancer. De plus, l’utilisation des nouvelles technologies issues de la génomique, de la protéomique et de la métabolomique ainsi que de nouvelles approches thérapeutiques issues des biotechnologies comme l’utilisation des anticorps monoclonaux humanisés, des protéines recombinantes, des siARN, ouvre également de multiples voies de découverte et de potentiel thérapeutique. Les connaissances nouvelles et les progrès technologiques associés devraient permettre d’améliorer l’identification et la validation du choix de cibles thérapeutiques nouvelles, le développement et l’intégration de biomarqueurs au sein des projets de la recherche et du développement, d’approfondir la connaissance du mécanisme d’action moléculaire et d’améliorer l’effet thérapeutique des futurs médicaments. Ils permettront également une meilleure caractérisation des modèles précliniques afin d’améliorer leur pouvoir prédictif par rapport à la pathologie humaine. C’est dans ce contexte de renouvellement des approches et des méthodes que nous évoquerons, dans cette revue, les évolutions des modèles de fonctionnement de l’industrie. Ces évolutions permettent de passer d’une recherche traditionnelle à une recherche translationnelle, où le patient et la physiopathologie sont mis au centre du processus de recherche et développement. Ce processus intègre l’utilisation de nouveaux outils de médecine moléculaire et de découverte de nouveaux biomarqueurs.
Abstract
Despite continued increase in global Pharma R & D expenditure, the number of innovative drugs obtaining market approval has declined since 1994. The pharmaceutical industry is now entering a crucial juncture where increasing rates of attrition in clinical drug development as well as increasing development timelines are impacted by external factors such as intense regulatory pricing and safety pressures, increasing sales erosion due to generics, as well as exponential increases in the costs of bringing a drug to market. Despite these difficulties, numerous opportunities exist such as multiple unmet medical needs, the increasing incidence of certain diseases such as Alzheimer’s disease, cancer, diabetes and obesity due to demographic changes, as well as the emergence of evolving markets such as China, India, and Eastern Europe. Consequently, Pharma is now responding to this challenge by improving both the productivity and the innovation in its drug discovery and development pipelines. In this regard, the advent of new technologies and expertise such as genomics, proteomics, structural biology, and molecular informatics in an integrated systems biology approach also provides a powerful opportunity for Pharma to address some of these difficulties. The key features behind this new strategy imply a discovery process based on an improved understanding of the molecular mechanism of diseases and drugs, translational research that places the patient at the center of the research process, and the application of biomarkers throughout the discovery and development phases. Moreover, new paradigms are required to improve target validation and develop more predictive cellular and animal models of human pathologies, a greater capacity in informatics-based analysis, and, consequently, a greater access to the vast sources of accumulating biological data and its integrated analysis. In the present review, we will address some of these issues and in particular emphasize how the application of biomarkers could potentially lead to improved productivity, quality, and innovation in drug discovery and ultimately better and safer medicines with improved therapeutic efficacy in specific pathologies for targeted patients.
© 2009 médecine/sciences - Inserm / SRMS
Les défis de l’industrie pharmaceutique
L’industrie pharmaceutique est face à un défi constamment renouvelé : découvrir les médicaments de demain pour traiter de multiples besoins médicaux non couverts tout en améliorant constamment le taux de réussite de leur développement. De façon surprenante et malgré des coûts en R & D en constante augmentation, force est de constater une relative « raréfaction » de nouvelles molécules innovantes arrivant sur le marché [1]. Cette pression concurrentielle pour l’innovation est de plus accrue par les critères de sécurité et d’efficacité toujours plus ambitieux. Certains de ces facteurs conduisent à des temps de développement de plus en plus longs et par conséquent, une durée d’exclusivité des brevets plus limitée, et inévitablement une érosion des parts de marché du médicament par l’arrivée des génériques.
Les taux de réussite des différentes phases du développement clinique des médicaments sont particulièrement intéressants à étudier [2, 3]. Entre 1990 et 2004, les plus grands groupes pharmaceutiques ont montré un taux d’échec de l’ordre de 90 % entre la phase 1 et l’Autorisation de la Mise sur le Marché (AMM), et de 50 % entre la phase 3 et l’AMM. Tous les axes thérapeutiques sont touchés par ce constat, mais tout particulièrement le cancer et les maladies touchant au système nerveux central. Les raisons de ces échecs sont multiples et complexes mais il est clair que l’absence d’efficacité clinique et un rapport bénéfice/risque trop faible en sont les facteurs principaux. L’industrie pharmaceutique ne peut assumer ce lourd investissement sans réduire le nombre d’échecs en clinique, et en parallèle, sans augmenter le nombre de médicaments innovants dans son portefeuille.
Les besoins et les opportunités
Malgré ces difficultés, il existe de multiples opportunités d’innovation thérapeutique ouvertes à l’industrie. L’évolution démographique de la population mondiale, l’allongement de la durée de vie et l’évolution des modes de vie augmentent l’incidence de certaines maladies chroniques et dégénératives (comme la maladie d’Alzheimer, l’ostéoporose), mais également du cancer, de l’obésité et du diabète ainsi que celle des nouvelles pathologies comme la multirésistance bactérienne qui représentent des enjeux majeurs de santé publique. Les améliorations médicales ont également transformé des maladies mortelles en maladies chroniques nécessitant des prises en charge à plus long terme. L’utilisation des nouvelles technologies issues de la génomique, de la protéomique, de la bio-informatique, de la métabolomique et des nouvelles approches thérapeutiques issues des biotechnologies comme l’utilisation des anticorps monoclonaux humanisés, des protéines recombinantes, des siARN, ouvre également de multiples voies de découverte et de potentiel thérapeutique.
Vers une meilleure connaissance des mécanismes moléculaires impliqués dans la maladie
« On fait la science avec des faits, comme on fait une maison avec des pierres : mais une accumulation de faits n’est pas plus une science qu’un tas de pierres n’est une maison ».
Henri Poincaré
Approches globales des systèmes biologiques
Pour relever les défis de l’innovation thérapeutique et saisir de telles opportunités, l’industrie pharmaceutique doit évoluer vers un nouveau système de pensée dans la découverte et vers un développement du médicament basé sur une compréhension globale des systèmes biologiques. En effet, une des clés du succès de ces médicaments de demain consiste en une meilleure connaissance de la maladie, incluant une connaissance approfondie des mécanismes moléculaires impliqués, ainsi que l’identification de fils conducteurs entre la préclinique et la clinique, entre les modèles animaux et les futurs patients, et ceci dès les stades de recherche (Voir Encadré ci-contre). En effet, si de multiples éléments peuvent être à l’origine des échecs des candidats médicaments en développement clinique, il apparaît de plus en plus fondamental de pouvoir définir les caractéristiques biologiques (biochimiques et physiologiques) de « l’état normal » et d’approfondir les mécanismes physiopathologiques et étiologiques impliqués dans la genèse et la progression des maladies chez l’homme.
En effet, la première étape dans cette démarche d’une meilleure connaissance des maladies est l’identification des cibles moléculaires impliquées dans le processus physiopathologique. Elle nécessite un lien fort et précoce entre la découverte du médicament et la recherche clinique dans un processus de recherche translationnelle (faisant intervenir les différentes compétences) pour lequel l’industrie crée peu à peu un nouvel environnement et instaure un nouveau mode de fonctionnement. Elle implique également la constitution de réseaux avec des partenaires académiques et hospitaliers, les autorités réglementaires ainsi que des consortiums de chercheurs à l’échelle européenne. Cette recherche innovatrice devra de plus être positionnée sur l’ensemble du cycle de vie d’un médicament, de la découverte jusqu’au lit du malade (« bench to bedside »).
La deuxième étape, sur la base d’une meilleure connaissance des mécanismes impliqués, est d’identifier des fils conducteurs, (bio)marqueurs permettant un suivi plus précis de l’évolution de la maladie et de l’activité pharmacologique et thérapeutique des futurs candidats médicaments. De plus, cette connaissance sera mieux traduite dans les nouveaux modèles animaux afin d’améliorer leur pouvoir prédictif en termes d’efficacité ou de toxicité clinique.
Ce continuum entre la recherche préclinique et clinique situe clairement les patients et la physiopathologie moléculaire au centre du processus de recherche afin de développer des médicaments innovants et plus efficaces et d’intégrer, dès le stade de recherche, la prévention, le diagnostic et le traitement des maladies. C’est dans ce cadre de recherche translationnelle et de médecine moléculaire que les nouvelles technologies développées après le séquençage du génome (ère post-génomique) apportent des outils permettant de mieux appréhender la complexité des pathologies chez l’homme. Elle regroupe les technologies de séquençage, de génétique moléculaire, de génomique fonctionnelle, de protéomique, de biologie structurale, de métabolomique, ainsi que les technologies d’imageries (IRM, SPECT, single photon emission computed tomography, PET, positron emission tomography) soutenues par de nouvelles méthodes d’analyse en bio-informatique, en biostatistique et en modélisation mathématique.

Ces approches permettent principalement de décrire, et par conséquent, de décortiquer l’entièreté d’un système biologique, allant du gène à son expression finale, la fonction. Elles permettent de mieux comprendre le mécanisme associé à la réponse aux médicaments (efficacité et effets secondaires) chez le patient et éventuellement de prédire les différentes sources de variabilité entre les individus. Ces nouvelles connaissances sont des sources importantes de propriétés intellectuelles.
Il faut avoir à l’esprit que les fonctions biologiques, qu’elles soient normales, pathologiques ou modulées par un médicament, sont la résultante d’une régulation coordonnée et dynamique de centaines de gènes ayant des répercussions sur l’expression, les modifications post-translationnelles, la localisation et la diversité de fonction des protéines. Par conséquent, les interprétations de ces processus, que l’on pourrait qualifier de « classiques » et canoniques, restent nécessairement des simplifications à la lumière des connaissances acquises ces dernières années. De plus, la multiplicité fonctionnelle des protéines ne peut s’imaginer que dans un flux permanent, dépendant de leur contexte cellulaire/tissulaire, de l’état physiologique/pathologique, des modifications post-traductionnelles, ou de leur interaction avec d’autres protéines.
C’est pourquoi une empreinte moléculaire obtenue à partir d’une analyse des ARN (transcriptome), des protéines (protéome) ou des métabolites (métabolome), ne représente qu’un instantané d’un phénomène biologique. La survenue de ces acteurs cellulaires est de plus échelonnée dans le temps et c’est pourquoi ils doivent nécessairement être mis en regard d’autres paramètres (qualitatifs et quantitatifs) comme les fonctions anatomiques, biochimiques, phénotypiques, cliniques et fonctionnelles du système étudié. On comprend alors mieux pourquoi il est nécessaire d’avoir une compréhension globale d’un système biologique dans une approche qualifiée aujourd’hui de biologie de système (systems biology). Elle représente en fait l’intégration de ces disciplines et de ces expertises nouvelles avec des connaissances plus établies et surtout la compréhension de leur imbrication.
Intégration des données
Ces nouvelles technologies ne peuvent cependant à elles seules résoudre tous les problèmes et si elles permettent indéniablement de mieux apprivoiser la complexité des processus en jeu, elles doivent nécessairement être appliquées en parallèle à d’autres approches et être à la portée (utilisable et compréhensible) des différents partenaires impliqués dans le projet.
En effet, la puissance de ces technologies en termes de genèse de données et d’informations oblige à être encore plus précis et plus rigoureux dans leur application et leur interprétation.
La première règle d’or est de préciser l’objectif scientifique que l’on veut atteindre et de déterminer si l’approche proposée permet de répondre à la question posée. L’intégration de ces méthodes doit se faire lors de la mise en place du plan d’expérience permettant de définir les analyses statistiques les plus appropriées.
La deuxième règle d’or est la mise en place d’une bonne organisation et d’un tri intelligent de ces données. En effet la quantité vertigineuse de données publiées quotidiennement sur ces sujets dans la recherche biomédicale (~ 1 700 publications par jour sont publiées dans PubMed) et la masse de données générées par des nouvelles technologies, nécessitent la mise en place d’outils de tri et de synthèse ainsi que des bases de données permettant de gérer, organiser, comparer, fédérer et analyser ces informations via des processus standardisés.
La bonne construction de cette architecture relationnelle est vitale pour une bonne exploitation et une bonne valorisation des données. Elle a souvent été négligée par le passé, mais représente la clé de voûte de l’approche des systèmes biologiques, bien avant les techniques d’analyses de laboratoire elles-mêmes.
Il en est de même pour les nouvelles méthodes d’analyses et d’expertises en biostatistique, mathématique de modélisation et en bio-informatique qui sont essentielles pour transformer ces informations en connaissances moléculaires utilisables.
Malgré les efforts pour mettre en place une organisation rationnelle, ces avancées technologiques peuvent donner quelque peu le tournis car elles vont au-delà des barrières des disciplines traditionnellement acceptées et forcent les scientifiques à trouver une nouvelle manière de travailler et de partager l’information. Cette évolution implique aujourd’hui, encore plus qu’hier, une discussion, une explication et une information quant au potentiel de ces approches et c’est dès la mise en place d’un nouveau projet thérapeutique que ces rôles et ces interconnexions de disciplines doivent être définis.
Finalement, la « validation » d’une nouvelle cible thérapeutique a souvent à tort été assimilée à un puzzle, où il fallait attendre la mise en place de la dernière pièce (fin de la phase 3), avant de valider son rôle dans le processus physiopathologique de la maladie principalement par le biais de l’efficacité ou de l’inefficacité du candidat médicament.
Il faut se rappeler que beaucoup de médicaments n’ont pas de cibles réelles identifiées et dans certains cas les composés ont des cibles multiples qui exigent une optimisation dès le stade de la recherche afin d’obtenir une efficacité et une sécurité clinique optimales.
De plus, la complexité de certaines maladies dégénératives et la limite actuelle des connaissances des processus moléculaires impliqués rendent extrêmement difficile le développement des médicaments ayant un impact majeur sur l’étiologie ou sur la progression de la maladie et en conséquence, limitent les remèdes à des traitements symptomatiques.
Or, si l’accès au tissu d’origine humaine (normal/pathologique) via des biobanques, la recherche clinique, les études médico-épidémiologiques, les essais cliniques et les observations médicales servent à enrichir notre connaissance des maladies, cela ne peut qu’aller de pair avec une meilleure connaissance des processus moléculaires à l’origine des maladies ainsi que de l’identification des cibles qui jouent un rôle majeur dans le processus physiopathologique. Cette démarche permet de faire émerger de nouvelles hypothèses et de consolider la pertinence du choix d’une cible pour un futur médicament, augmentant ainsi les chances de succès d’avoir un impact sur la pathologie et l’état clinique du patient. Cette approche offre l’opportunité d’identifier les sous-populations de patients susceptibles de mieux bénéficier du traitement.
Pour relever le défi de l’intégration et de l’application de ces nouvelles technologies au sein du groupe Servier, il a été créé un ensemble de plates-formes, véritables « boîtes à outils » technologiques, mises à la disposition des partenaires de la Recherche et Développement (Figure 1). Au sein de la recherche, la division de pharmacologie et physiopathologie moléculaires fédère de multiples expertises et technologies couvrant les domaines de la génomique, de la protéomique, de la bio-informatique et de la pathologie moléculaire. Elle a pour objectif d’améliorer la validation du choix des cibles thérapeutiques. Elle permet une meilleure caractérisation et un suivi des modèles précliniques afin d’améliorer leur pouvoir prédictif par rapport à la pathologie humaine. Ces outils permettent le développement et l’intégration de biomarqueurs pharmacodynamiques au sein des projets de recherche et d’approfondir la connaissance du mécanisme d’action moléculaire de nos futurs médicaments.
 |
Figure 1. Fédération au sein du groupe Servier de l’ensemble des expertises et technologies nécessaires à une démarche translationnelle. Elle couvre les domaines de la génomique, de la protéomique, de la biochimie métabolique, de la bio-informatique et la pathologie moléculaire. |
L’intégration de ces nouvelles technologies dans les programmes de développement de nouveaux médicaments se poursuit dans les domaines de la biopharmacie et de la clinique. Elle concerne notamment la sécurité d’emploi des médicaments (toxicogénomique), le métabolisme, avec la biochimie métabolique (métabolomique), qui permettent de suivre les modifications métaboliques exogènes et endogènes induites ou reliées au traitement ainsi que les études de pharmacogénétiques pour la caractérisation des variabilités de réponses aux traitements.
Cette synergie de compétences et de moyens est essentielle pour mieux apprivoiser la complexité du système biologique du gène jusqu’aux effets fonctionnels moléculaires physiologiques et/ou pathologiques. Mais cette démarche d’innovation thérapeutique et de recherche exploratoire doit être synchronisée avec les programmes de recherche afin de mieux comprendre les mécanismes en jeu et à terme de faciliter la prise de décision dans l’avancée des projets.
Le pouvoir prédictif des modèles animaux est au centre de nos préoccupations car il est un des éléments fortement liés aux échecs en clinique [4–7]. C’est pourquoi nous étudions très en amont le tissu pathologique humain ce qui nous permet, dès le stade de découverte, de valider le rôle fonctionnel de la cible dans la pathologie humaine et de mieux sélectionner et développer les modèles précliniques. Nous nous appliquons également à déterminer si ces modèles animaux sont adaptés à la cible moléculaire étudiée (relation cible, processus physiopathologique et symptomatologique). Souvent, il nous manque de nombreux éléments fondamentaux permettant de caractériser ces modèles. Il faut donc déterminer des facteurs aussi divers que le niveau d’expression, la régulation et le rôle fonctionnel de la cible, les études d’homologies entre protéines, l’extrapolation entre espèces (orthologie), les variations génétiques qui influent sur la fonction ainsi que la localisation tissulaire et cellulaire de ces cibles.
Mais la compréhension de la similarité/dissimilarité entre espèces ne s’arrête pas au niveau moléculaire, il faut y intégrer la dimension histopathologique. C’est pourquoi nous pensons que les expertises en histologie et anatomopathologie sont un atout majeur de cette stratégie. L’introduction des modèles animaux (pathology-driven) par l’utilisation de modèles transgéniques, qui reproduisent aux niveaux moléculaire et pathologique la génétique, l’étiologie et le développement de la maladie, est une voie d’amélioration des modèles « génériques » très utilisée dans la recherche biomédicale [8].
Le domaine du diabète est caractéristique de cette démarche d’amélioration de connaissances du modèle animal. Par exemple, les souris db/db présentent une mutation dans le gène pour le récepteur de la leptine et développent plusieurs phénotypes et perturbations métaboliques typiques du diabète de type 2 comme l’hyperglycémie, l’hyperinsulinémie, l’hyperlipidémie et la résistance à l’insuline [9]. En effet, nous avons montré de très importantes modifications transcriptionnelles avec un changement d’expression d’environ 4 000-8 000 gènes en fonction du tissu analysé entre les db (animaux témoins) et les db/db (animaux pathologiques) (Tableau I). Si ce véritable embrasement transcriptionel est lié pour une part au processus physiopathologique, de nombreuses modifications concernent aussi des mécanismes d’adaptation de l’organisme à la progression de la pathologie. Il est à noter une augmentation significative des taux de plusieurs triglycérides, notamment du trilinoléate, trioléate, acide linoléique et de l’acide oléique du foie chez les souris db/db par rapport aux souris db+ (Figure 2). Une analyse conjointe des données de métabolomique (suivi des fonctions métaboliques) et de transcriptomique (modifications dans les transcriptions de gènes) nous permet de faire l’hypothèse suivante : l’augmentation de la densité de triglycérides et d’acide gras libres de souris db/db versus db+, dans le foie, pourrait être associée à l’augmentation des ARNm des gènes codant des transporteurs d’acides gras (CD36 ; × 13,6), ou des enzymes impliquées dans la voie de synthèse des acides gras telles que l’acétyl-CoA carboxylase a (ACACA ; × 1,5), l’enzyme de synthèse des acides gras (FAS ; × 2) et des triglycérides tels que la glycérol 3-phosphate déshydrogénase 3 (Gpd1 ; × 1,5) et l’acylglycérol-3- phosphate O- acyltransférase (Agpata2 ; × 1,6). Il est donc important de se focaliser sur des processus cellulaires et moléculaires associés aux manifestations fonctionnelles de la pathologie (insulinémie, stéatose, glycémie, etc.) et de faire le lien avec la cible thérapeutique étudiée dans ce modèle animal.
 |
Figure 2. Profil métabolomique des triglycérides au niveau du foie des souris diabétiques (db/db) et des souris témoins (db+) à l’âge de 12 semaines. Données : n = 6 animaux/groupe (moyenne ± ESM) ; test de Student (**p > 0,01, ***p < 0,001). |
Changements d’expression tissulaires des ARN (modifications transcriptionnelles - augmentation [induction] ou diminution [répression]) entre les souris diabétiques (db/db) et les souris témoins (db+) à 12 semaines. Données : n = 6 animaux/groupe. Nombre de séquences : facteur de régulation > 1,5 ; p < 0,01.
Les biomarqueurs et la variabilité de réponse aux traitements
Les médicaments et les médecins traitent par définition d’abord des individus et non des populations. Ceci est encore plus d’actualité dans l’ère du post-génome où la diversité génétique des individus s’est révélée plus complexe que prévue. Il y a probablement des millions de polymorphismes (SNP) différents entre chaque individu [10–11]. Cette diversité génétique a un impact sur la fonction de nombreuses protéines allant, dans la population, d’une absence totale de fonction jusqu’à une hyperexpression de certaines protéines (copies de gènes) en passant par des degrés divers de fonctionnalité. Ce type de distribution de fonctions dans une population est bien connu pour les protéines ADME [drug absorption, distribution, metabolism, and excretion] (enzymes et transporteurs) qui gouvernent le devenir du médicament dans l’organisme pendant les phases d’absorption, de distribution, de métabolisme et d’élimination des médicaments. La conséquence de ces variations génétiques du trafic cellulaire est une variabilité d’exposition au médicament et d’accès à la cible avec un impact direct sur l’activité des médicaments. Ce type d’influence a été démontré dans le cas du polymorphisme d’un transporteur d’entrée de la cellule hépatocytaire (SLCO1B1) qui limite l’entrée au site d’action hépatique du métabolite actif de la simvastatine et module ainsi son activité [12].
De nombreux polymorphismes sont également décrits au niveau des cibles pharmacologiques permettant de tenter d’expliquer des variabilités de réponse à des traitements médicamenteux ou d’être à l’origine d’identification de nouvelles cibles pharmacologiques. C’est ainsi que dans un travail récent, il a été démontré que des variants du gène de la sérine/thréonine kinase (STK39) peuvent influer sur la régulation de la pression sanguine en altérant l’excrétion rénale de sodium. Les protéines que régulent ces gènes pourraient ainsi être des cibles intéressantes pour de nouveaux traitements antihypertenseurs [13].
Mais la variabilité de réponse à un médicament est souvent la combinaison de plusieurs facteurs, ceci peut être illustré avec la variabilité de réponse observée pour l’anticoagulant la warfarine, composé pour lequel plus de 50 % de la variabilité de réponse est associé à des facteurs génétiques. Il implique des polymorphismes reliés au mécanisme d’action, celui de la vitamine K époxyde réductase (VKORC1) qui explique 30 % de la variabilité, mais également des enzymes hépatiques impliquées dans la transformation du médicament, le cytochrome P450 2C9 (CYP2C9) avec 12 % de la variabilité en moyenne [14] et plus récemment le cytochrome P450 4F2 (CYP4F2) impliqué dans le catabolisme des acides gras (8 % de la variabilité) a été corrélé à la réponse au traitement. Mais les autres facteurs de variabilité sont multiples et sont le reflet de la complexité des maladies avec une étiologie multifactorielle qui réunit les facteurs génétiques, épigénétiques, développementaux et environnementaux (âge, hypertension, surpoids, alcool, tabac, état de la microflore).
C’est pourquoi, en lien avec l’approche globale des « systèmes biologiques », une plus grande compréhension des voies de signalisation moléculaires et cellulaires impliquées dans les événements physiologiques et pathologiques, fournirait les bases de l’identification de nouveaux biomarqueurs. On peut ainsi définir trois principaux types de biomarqueurs utilisés en recherche biomédicale (préclinique et clinique) (Figure 3).
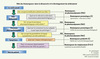 |
Figure 3. Intégration des biomarqueurs dans le processus de découverte et de développement des médicaments. Les biomarqueurs de pharmacodynamie doivent être utilisés le plus tôt possible afin de confirmer l’activité biologique du médicament (atteinte de la cible et/ou activité fonctionnelle et/ou efficacité thérapeutique). Les biomarqueurs sont également utilisés pour comprendre la physiopathologie (marqueurs prognostiques) et prédire l’efficacité thérapeutique (marqueurs prédictifs). De plus, la mesure des biomarqueurs qui sont modifiés par une thérapie et connus pour leur pertinence clinique et leur pouvoir prédictif du bénéfice thérapeutique (marqueurs de remplacement) serait une avancée majeure dans le développement d’un médicament. Les biomarqueurs de toxicité et de sécurité doivent être appliqués tout au long du processus de découverte et de développement clinique pour prédire éventuellement les effets secondaires associés aux modulations d’une cible moléculaire par une classe thérapeutique. |
Les marqueurs d’activité de pharmacodynamie qui permettent de confirmer l’activité biologique du médicament (atteinte de la cible ou efficacité thérapeutique) utiles à l’optimisation des décisions en recherche ou en clinique, du protocole et du choix de la dose.
Les marqueurs prédictifs qui sont corrélés avec l’activité thérapeutique du médicament, permettent d’identifier la population à même d’en bénéficier le plus.
Les marqueurs pronostiques, qui sont corrélés avec l’issue de la maladie indépendamment d’un traitement médicamenteux. Ils reflètent le processus physiopathologique de la maladie (ex : Her-2 est un mauvais marqueur pronostique du cancer du sein mais un marqueur prédictif de la réponse au trastuzumab [Herceptine®]).
Le processus de découverte et de développement d’un médicament est complexe, il faut identifier une molécule qui est capable d’interagir avec une cible moléculaire, en modifier son fonctionnement, puis altérer des processus physiopathologiques impliqués dans la maladie ou sa symptomatologie et ce dans le but d’améliorer l’état du patient (Figure 3). Les biomarqueurs d’activité fournissent les méthodes permettant de répondre objectivement à ces différentes phases. Les biomarqueurs prédictifs et pronostiques permettent quant à eux de mieux sélectionner les patients, d’améliorer le schéma des études cliniques et leur interprétation. Ils fournissent des informations pertinentes dans la démarche de découverte (ex : l’identification des cibles critiques dans le processus physiopathologique) [15].
Tous ces biomarqueurs permettent l’évaluation précoce de l’efficacité de l’intervention thérapeutique sur une cible et sur le processus pathologique, par une stratification des patients afin d’améliorer les taux de réponses et éviter les effets secondaires. En fait, ils fournissent des informations qui permettent de lier le mécanisme d’action d’un composé à son efficacité thérapeutique. Une meilleure utilisation des biomarqueurs d’efficacité et de sécurité renforcerait le processus de validation de l’hypothèse physiopathologique et de l’efficacité thérapeutique avec un impact direct sur le rapport bénéfice/risque de nos médicaments. À ce titre ce sont des outils prédictifs indispensables dans tout le cycle de vie du médicament.
Le concept de médecine personnalisée est basé sur la stratification des patients permettant d’identifier des sous-populations de patients qui répondraient mieux en termes d’efficacité ou d’effets secondaires à un nouveau médicament [16]. Les biomarqueurs permettent d’améliorer la qualité des essais cliniques et peuvent être des marqueurs de substitution d’efficacité thérapeutique.
Mais l’identification de nouveaux biomarqueurs cliniques nécessitera régulièrement une validation préalable par la mise en place des réseaux nationaux et internationaux travaillant de façon coordonnée sur les mêmes procédures de standardisation et de validation.
Les médecins manquent encore d’un grand nombre d’outils diagnostiques précis, mais également de pratique, pour traiter des patients avec une approche ciblée. L’introduction du principe de la preuve de mécanisme (proof-in-mechanism), très tôt dans le processus de recherche, pour valider le rôle de la cible dans le processus physiopathologique avec les partenaires cliniciens, est une étape critique. Cette première phase doit être immédiatement suivie par des études cliniques précoces capables de mieux prédire l’efficacité thérapeutique et la sécurité du candidat médicament. L’utilisation de biomarqueurs dès cette étape contribuera à conforter les hypothèses initiales, et ce avant d’engager des études de phase 3 longues et coûteuses.
En conclusion
Les progrès dans la connaissance moléculaire des processus physiopathologiques de maladies pour lesquelles les besoins thérapeutiques restent majeurs permettraient d’identifier de nouvelles cibles pharmacologiques ou de nouveaux biomarqueurs d’intérêt. Cette connaissance offre les perspectives de faire émerger des innovations thérapeutiques, d’accroître l’efficacité thérapeutique pour des sous-populations de patients identifiées sur la base de marqueurs moléculaires pertinents, d’accélérer les phases de développement clinique voir d’en réduire le risque et éventuellement les coûts
Remerciements
Nous remercions J.P. Galizzi, N. Guigal-Stéphan, S. Le Bouter, C. Boursier et T. Umbdenstock.
Références
- Schmid F, Smith DA. Is declining innovation in the pharmaceutical industry a myth ? Drug Discov Today 2005; 10 : 1031–9. [Google Scholar]
- Kola I, Landis J. Can the pharmaceutical industry reduce attrition rates ? Nat Rev Drug Discov 2004; 3 : 711–4. [Google Scholar]
- Kola I, Hazuda D. Innovation and greater probability of success in drug discovery and development: from target to biomarkers. Curr Opin Biotechnol 2005; 16 : 644–6. [Google Scholar]
- Sams-Dodd F. Strategies to optimize the validity of disease models in the drug discovery process. Drug Discov Today 2006; 11 : 355–63. [Google Scholar]
- Graeber TG, Sawyers CL. Cross-species comparisons of cancer signaling. Nat Genet 2005; 37 : 7–8. [Google Scholar]
- Kamb A. What’s wrong with our cancer models ? Nat Rev Drug Discov 2005; 4 : 161–5. [Google Scholar]
- Littman BH, Williams SA. The ultimate model organism: progress in experimental medicine. Nat Rev Drug Discov 2005; 4 : 631–8. [Google Scholar]
- Sharpless NE, DePinho RA. The mighty mouse: genetically engineered mouse models in cancer drug development. Nat Rev Drug Discov 2006; 5 : 741–54. [Google Scholar]
- Chen H, Churfat O, Tartaglia LA, et al. Evidence that the diabetes gene encodes the leptin receptor: identification of a mutation in the leptin receptor gene in db/db mice. Cell 1996; 84 : 491–5. [Google Scholar]
- Roses AD. Pharmacogenetics and the practice of medicine. Nature 2000; 405 : 857–65. [Google Scholar]
- Johnson JA. Pharmacogenetics: potential for individualized drug therapy through genetics. Trends Genet 2003; 19(11) : 660–6. [Google Scholar]
- Pasanen MK. SLC01B1 polymorphism markedly affects the pharmacokinetics of simvastatin acid. Pharmacogenet Genomics 2006; 16 : 873–9. [Google Scholar]
- Wang Y, et al. Whole-genome association study identifies STK39 as a hypertension susceptibility gene. Proc Natl Acad Sci USA 2009; 106 : 226–31. [Google Scholar]
- Caldwell MD. CYP4F2 genetic variant alters required warfarin dose. Blood 2008; 111 : 4106–12. [Google Scholar]
- Frank R, Hargreaves R. Clinical biomarkers in drug discovery and development. Nat Rev Drug Discov 2003; 2 : 566–80. [Google Scholar]
- Trusheim MR, Berndt ER, Douglas FL. Stratified medicine: strategic and economic implications of combining drugs and clinical biomarkers. Nat Rev Drug Discov 2007; 6 : 287–93. [Google Scholar]
Liste des tableaux
Changements d’expression tissulaires des ARN (modifications transcriptionnelles - augmentation [induction] ou diminution [répression]) entre les souris diabétiques (db/db) et les souris témoins (db+) à 12 semaines. Données : n = 6 animaux/groupe. Nombre de séquences : facteur de régulation > 1,5 ; p < 0,01.
Liste des figures
|
Figure 1. Fédération au sein du groupe Servier de l’ensemble des expertises et technologies nécessaires à une démarche translationnelle. Elle couvre les domaines de la génomique, de la protéomique, de la biochimie métabolique, de la bio-informatique et la pathologie moléculaire. |
| Dans le texte | |
|
Figure 2. Profil métabolomique des triglycérides au niveau du foie des souris diabétiques (db/db) et des souris témoins (db+) à l’âge de 12 semaines. Données : n = 6 animaux/groupe (moyenne ± ESM) ; test de Student (**p > 0,01, ***p < 0,001). |
| Dans le texte | |
|
Figure 3. Intégration des biomarqueurs dans le processus de découverte et de développement des médicaments. Les biomarqueurs de pharmacodynamie doivent être utilisés le plus tôt possible afin de confirmer l’activité biologique du médicament (atteinte de la cible et/ou activité fonctionnelle et/ou efficacité thérapeutique). Les biomarqueurs sont également utilisés pour comprendre la physiopathologie (marqueurs prognostiques) et prédire l’efficacité thérapeutique (marqueurs prédictifs). De plus, la mesure des biomarqueurs qui sont modifiés par une thérapie et connus pour leur pertinence clinique et leur pouvoir prédictif du bénéfice thérapeutique (marqueurs de remplacement) serait une avancée majeure dans le développement d’un médicament. Les biomarqueurs de toxicité et de sécurité doivent être appliqués tout au long du processus de découverte et de développement clinique pour prédire éventuellement les effets secondaires associés aux modulations d’une cible moléculaire par une classe thérapeutique. |
| Dans le texte | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.